이 튜토리얼에서는 다음을 사용하는 방법을 배웁니다. SUM 함수구문과 예제가 포함된 SQL Server(Transact-SQL).
설명
SQL Server(Transact-SQL)에서 SUM 함수표현식의 총 값을 반환합니다.
통사론
SQL Server(Transact-SQL)의 SUM 함수 구문은 다음과 같습니다.
또는 하나 이상의 열로 결과를 그룹화할 때 SUM 함수의 구문은 다음과 같습니다.
매개변수 또는 인수
표현식1 , 표현식2 , ... 표현식_n 은 SUM 함수에 포함되지 않는 표현식으로 SQL 문 끝의 GROUP BY 절에 포함되어야 합니다.
Aggregate_expression은 집계될 열 또는 표현식입니다.
테이블 - 레코드를 가져오려는 테이블입니다. FROM 절에는 테이블이 하나 이상 나열되어 있어야 합니다.
WHERE 조건 - 선택 사항입니다. 이는 선택한 레코드에 대해 충족되어야 하는 조건입니다.
애플리케이션
SUM 함수는 다음 버전의 SQL Server(Transact-SQL)에서 사용할 수 있습니다.
SQL Server vNext, SQL Server 2016, SQL Server 2015, SQL Server 2014, SQL Server 2012, SQL Server 2008 R2, SQL Server 2008, SQL Server 2005
필드가 1개인 예
SQL Server(Transact-SQL)에서 SUM 함수를 사용하는 방법을 이해하기 위해 몇 가지 SQL Server SUM 함수 예제를 살펴보겠습니다.
예를 들어 수량이 10보다 큰 모든 제품의 총 수량을 확인할 수 있습니다.
SUM 함수의 이 예에서는 SUM(수량) "총 수량" 표현식에 별칭을 지정했습니다. 결과 세트를 반환할 때 "총 수량"이 필드 이름으로 나타납니다.
DISTINCT 사용 예
SUM 함수에 DISTINCT 연산자를 사용할 수 있습니다. 예를 들어 아래 SQL 문은 급여가 연간 $29,000 미만인 고유한 급여 값을 사용하여 총 급여를 반환합니다.
두 급여가 연간 $24,000인 경우 해당 값 중 하나만 SUM 함수에 사용됩니다.
수식 사용 예
SUM 함수에 포함된 표현식은 단일 필드일 필요는 없습니다. 공식을 사용할 수도 있습니다. 예를 들어 총 수수료를 계산할 수 있습니다.
Transact-SQL
SELECT SUM(sales * 0.03) AS "총 커미션" FROM 주문;
SELECT SUM (판매액 * 0.03 ) AS "총 커미션" 주문에서; |
GROUP BY 사용 예
경우에 따라 SUM 함수와 함께 GROUP BY 연산자를 사용해야 합니다.
특정 공급업체가 생산한 PC 모델 수를 어떻게 알 수 있나요? 동일한 기술적 특성을 가진 컴퓨터의 평균 가격을 결정하는 방법은 무엇입니까? 일부 통계 정보와 관련된 이러한 질문과 기타 많은 질문은 다음을 사용하여 답변할 수 있습니다. 최종(집계) 함수. 표준은 다음과 같은 집계 함수를 제공합니다.
이러한 함수는 모두 단일 값을 반환합니다. 동시에, 기능 개수, 최소그리고 최대모든 데이터 유형에 적용 가능하지만 합집합그리고 평균숫자 필드에만 사용됩니다. 기능의 차이 세다(*)그리고 세다(<имя поля>) 두 번째는 계산할 때 NULL 값을 고려하지 않는다는 것입니다.
예. 개인용 컴퓨터의 최소 및 최대 가격을 찾으십시오.
예. 제조업체 A에서 생산할 수 있는 컴퓨터 수를 찾으십시오.
예. 제조업체 A가 생산한 다양한 모델의 수에 관심이 있는 경우 쿼리는 다음과 같이 공식화될 수 있습니다(제품 테이블에 각 모델이 한 번 기록된다는 사실을 사용).
예. 제조업체 A가 생산한 사용 가능한 다양한 모델의 수를 찾으십시오. 쿼리는 제조업체 A가 생산한 총 모델 수를 확인해야 했던 이전 쿼리와 유사합니다. 여기서는 다음에서 다양한 모델의 수도 찾아야 합니다. PC 테이블(즉, 판매 가능한 테이블)
통계 지표를 얻을 때 고유한 값만 사용되도록 하려면 집계 함수의 인수사용될 수 있다 DISTINCT 매개변수. 또 다른 매개변수 전체기본값이며 열의 모든 반환 값이 계산된다고 가정합니다. 운영자,
생산된 PC 모델 수를 알아야 하는 경우 모든 사람제조업체에 따라 사용해야 합니다. GROUP BY 절, 구문상 다음과 같습니다. WHERE 절.
GROUP BY 절
GROUP BY 절다음에 적용할 수 있는 출력 라인 그룹을 정의하는 데 사용됩니다. 집계 함수(COUNT, MIN, MAX, AVG 및 SUM). 이 절이 누락되고 집계 함수가 사용되는 경우에는 이름이 언급된 모든 열이 선택하다, 에 포함되어야 합니다. 집계 함수, 이러한 함수는 쿼리 조건자를 충족하는 전체 행 집합에 적용됩니다. 그렇지 않으면 SELECT 목록의 모든 열이 포함되지집계 함수를 지정해야 합니다. GROUP BY 절에서. 결과적으로, 모든 출력 쿼리 행은 해당 열의 동일한 값 조합을 특징으로 하는 그룹으로 나뉩니다. 이후에는 각 그룹에 집계 함수가 적용됩니다. GROUP BY의 경우 모든 NULL 값은 동일하게 취급됩니다. NULL 값이 포함된 필드를 기준으로 그룹화하면 이러한 모든 행이 하나의 그룹에 속하게 됩니다.만약에 GROUP BY 절이 있는 경우, SELECT 절에서 집계 함수 없음, 그러면 쿼리는 단순히 각 그룹에서 하나의 행을 반환합니다. 이 기능은 DISTINCT 키워드와 함께 결과 집합에서 중복 행을 제거하는 데 사용할 수 있습니다.
간단한 예를 살펴보겠습니다.
| SELECT 모델, COUNT(모델) AS Qty_model, AVG(가격) AS Avg_price PC에서 모델별로 그룹화; |
이 요청에서는 각 PC 모델에 대해 모델 수와 평균 비용이 결정됩니다. 동일한 모델 값을 가진 모든 행이 그룹을 형성하고 SELECT의 출력은 각 그룹에 대한 값의 개수와 평균 가격 값을 계산합니다. 쿼리 결과는 다음 표와 같습니다.
| 모델 | 수량_모델 | 평균 가격 |
| 1121 | 3 | 850.0 |
| 1232 | 4 | 425.0 |
| 1233 | 3 | 843.33333333333337 |
| 1260 | 1 | 350.0 |
SELECT에 날짜 열이 있는 경우 각 특정 날짜에 대해 이러한 표시기를 계산할 수 있습니다. 이렇게 하려면 날짜를 그룹화 열로 추가해야 하며, 그런 다음 각 값 조합(모델-날짜)에 대해 집계 함수가 계산됩니다.
몇 가지 구체적인 내용이 있습니다 집계 함수 수행 규칙:
- 요청에 따른 결과인 경우 수신된 행이 없습니다.(또는 특정 그룹에 대해 둘 이상의 행), 집계 함수를 계산하기 위한 소스 데이터가 없습니다. 이 경우 COUNT 함수의 결과는 0이 되고, 다른 모든 함수의 결과는 NULL이 됩니다.
- 논쟁집계 함수 그 자체로는 집계 함수를 포함할 수 없습니다.(함수에서 함수). 저것들. 예를 들어 한 쿼리에서는 최대 평균값을 얻는 것이 불가능합니다.
- COUNT 함수를 실행한 결과는 다음과 같습니다. 정수(정수). 다른 집계 함수는 처리하는 값의 데이터 유형을 상속합니다.
- SUM 함수가 사용된 데이터 유형의 최대값보다 큰 결과를 생성하는 경우 오류.
따라서 요청에 포함되지 않은 경우 GROUP BY 절, 저것 집계 함수포함 된 SELECT 절, 모든 결과 쿼리 행에 대해 실행됩니다. 요청에 다음이 포함된 경우 GROUP BY 절, 지정된 열 또는 열 그룹의 값이 동일한 각 행 집합 GROUP BY 절, 그룹을 구성하고 집계 함수각 그룹별로 개별적으로 수행됩니다.
제안을 받음
만약에 WHERE 절행 필터링을 위한 조건자를 정의한 다음 제안을 받음적용됩니다 그룹화 후값별로 그룹을 필터링하는 유사한 조건자를 정의합니다. 집계 함수. 이 절은 다음을 사용하여 얻은 값을 검증하는 데 필요합니다. 집계 함수다음에 정의된 레코드 원본의 개별 행이 아닌 FROM 절, 그리고 에서 그러한 라인의 그룹. 따라서 그러한 수표는 다음에 포함될 수 없습니다. WHERE 절.
SQL 언어의 SUM 함수는 단순함에도 불구하고 데이터베이스 작업 시 자주 사용됩니다. 도움을 받으면 보조 DBMS 도구의 도움을 받지 않고도 중간 또는 최종 결과를 얻는 것이 편리합니다.
함수 구문
대부분의 SQL 언어에서 합계 구문은 동일합니다. 즉, 필드 이름이나 일부 산술 연산만 합계가 필요한 인수로 사용됩니다.
예외적인 경우에는 특정 값을 숫자나 변수로 전송할 수 있지만 이러한 "구성표"는 많은 값을 전달하지 않기 때문에 실제로 사용되지 않습니다. 다음은 SQL의 함수 구문입니다.
sum(a) - 여기서는 숫자 값이나 표현식이 매개변수로 사용됩니다.
매개변수 앞에 키워드(예: 각각 고유한 값만 사용하거나 모든 값을 사용하는 DISTINCT 또는 ALL)를 설정할 수 있다는 점은 주목할 가치가 있습니다.
SQL에서 SUM을 사용하는 예
기능이 어떻게 작동하는지 완전히 이해하려면 몇 가지 예를 고려해 볼 가치가 있습니다. SQL에서 SUM은 반환 결과와 중간 값(예: 조건 테스트)으로 모두 사용될 수 있습니다.
첫 번째 경우에는 구매 횟수가 복수일 수 있다는 점을 고려하여 각 제품의 판매량을 반환해야 하는 옵션을 고려합니다. 결과를 얻으려면 다음 쿼리를 실행하면 충분합니다.
SELECT 제품, sum(PurchaseAmount) FROM Sales GroupBy;
이 명령에 대한 응답은 각 제품의 총 구매 금액이 포함된 고유한 제품 목록입니다.

두 번째 예에서는 판매량이 특정 값(예: 100)을 초과한 제품 목록을 가져와야 합니다. 이 작업에 대한 결과는 여러 가지 방법으로 얻을 수 있으며 그 중 가장 최적의 방법은 하나의 요청을 실행하는 것입니다.
SELECT Product FROM (SELECT Product, sum(구매 금액) as Amount FROM Sales) WHERE Sum > 100.
SQL - 11과. 총계 함수, 계산된 열 및 뷰
총계 함수는 통계, 집계 또는 합계 함수라고도 합니다. 이러한 함수는 일련의 문자열을 처리하여 단일 값을 계산하고 반환합니다. 이러한 기능은 5개만 있습니다.- AVG() 함수는 열의 평균 값을 반환합니다.
- COUNT() 함수는 열의 행 수를 반환합니다.
- MAX() 함수는 열에서 가장 큰 값을 반환합니다.
- MIN() 함수는 열에서 가장 작은 값을 반환합니다.
- SUM() 이 함수는 열 값의 합계를 반환합니다.
SELECT MIN(가격), MAX(가격), AVG(가격) FROM 가격;

이제 우리는 공급자 "House of Printing"(id=2)이 우리에게 가져온 상품의 양을 확인하려고 합니다. 그런 요청을 하는 것은 그리 쉬운 일이 아닙니다. 그것을 구성하는 방법에 대해 생각해 봅시다:
1. 먼저 공급(수신) 테이블에서 공급업체 "인쇄소"(id=2)가 수행한 배송의 식별자(id_incoming)를 선택합니다.

2. 이제 공급 일지 테이블(magazine_incoming)에서 항목 1에서 찾은 배송에서 수행된 상품(id_product)과 해당 수량(수량)을 선택해야 합니다. 즉, 지점 1의 쿼리가 중첩됩니다.
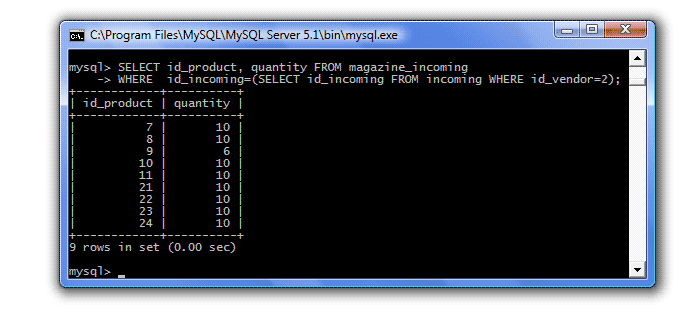
3. 이제 가격 테이블에 저장된 검색된 제품의 가격을 결과 테이블에 추가해야 합니다. 즉, id_product 열을 사용하여 Supply Magazine(magazine_incoming) 및 가격 테이블을 조인해야 합니다.

4. 결과 테이블에는 Amount 열이 분명히 없습니다. 계산된 열. 이러한 열을 생성하는 기능은 MySQL에서 제공됩니다. 이렇게 하려면 쿼리에서 계산된 열의 이름과 계산 대상을 지정하기만 하면 됩니다. 이 예에서는 이러한 열을 summa라고 하며 수량 열과 가격 열의 곱을 계산합니다. 새 열의 이름은 AS라는 단어로 구분됩니다.
SELECT magazine_incoming.id_product, magazine_incoming.Quantity, 가격.price, magazine_incoming.Quantity*prices.price AS 요약 FROM magazine_incoming, 가격 WHERE magazine_incoming.id_product= 가격.id_product AND id_incoming= (SELECT id_incoming FROM 수신 WHERE id_vendor=2);

5. 좋습니다. 우리가 해야 할 일은 합계 열을 합산하고 마지막으로 "House of Printing" 공급업체가 우리에게 상품을 가져온 가격이 얼마인지 알아내는 것뿐입니다. SUM() 함수를 사용하는 구문은 다음과 같습니다.
SELECT SUM(열_이름) FROM 테이블_이름;
우리는 열 이름(summa)을 알고 있지만 테이블 이름은 쿼리 결과이기 때문에 알 수 없습니다. 무엇을 해야 할까요? 이러한 경우 MySQL에는 뷰가 있습니다. 뷰는 고유한 이름이 부여되고 나중에 사용하기 위해 데이터베이스에 저장할 수 있는 선택 쿼리입니다.
뷰를 생성하는 구문은 다음과 같습니다.
CREATE VIEW view_name AS 요청;
요청을 report_vendor라는 뷰로 저장해 보겠습니다.
CREATE VIEW report_vendor AS SELECT magazine_incoming.id_product, magazine_incoming.Quantity, rates.price, magazine_incoming.Quantity*prices.price AS summa FROM magazine_incoming, 가격 WHERE magazine_incoming.id_product= 가격.id_product AND id_incoming= (수신 WHERE id_vendor=2에서 id_incoming 선택 );
6. 이제 최종 함수 SUM()을 사용할 수 있습니다.
SELECT SUM(summa) FROM report_vendor;

따라서 결과를 얻었지만 이를 위해서는 중첩 쿼리, 조인, 계산된 열 및 뷰를 사용해야 했습니다. 예, 때로는 결과를 얻기 위해 생각해야 합니다. 이것이 없으면 아무데도 얻을 수 없습니다. 그러나 우리는 계산된 열과 뷰라는 두 가지 매우 중요한 주제를 다루었습니다. 그들에 대해 더 자세히 이야기합시다.
계산된 필드(열)
오늘은 예를 사용하여 수학적 계산 필드를 살펴보았습니다. 여기서는 곱셈연산(*) 뿐만 아니라 뺄셈(-), 덧셈(+), 나눗셈(/)도 사용할 수 있다는 점을 덧붙이고 싶습니다. 구문은 다음과 같습니다.SELECT 열 이름 1, 열 이름 2, 열 이름 1 * 열 이름 2 AS 계산_열 이름 FROM 테이블_이름;
두 번째 뉘앙스는 AS 키워드입니다. 이를 사용하여 계산된 열의 이름을 설정했습니다. 실제로 이 키워드는 모든 열에 대한 별칭을 설정하는 데 사용됩니다. 이것이 왜 필요한가요? 코드 감소 및 가독성을 위해. 예를 들어 뷰는 다음과 같습니다.
CREATE VIEW report_vendor AS SELECT A.id_product, A.Quantity, B.price, A.Quantity*B.price AS summa FROM magazine_incoming AS A, 가격 AS B WHERE A.id_product= B.id_product AND id_incoming= (SELECT id_incoming FROM 수신 어디에서 id_vendor=2);
이것이 훨씬 더 짧고 명확하다는 데 동의하십시오.
대표
우리는 이미 뷰를 생성하는 구문을 살펴보았습니다. 뷰가 생성되면 테이블과 동일한 방식으로 사용할 수 있습니다. 즉, 이에 대해 쿼리를 실행하고, 데이터를 필터링 및 정렬하고, 일부 보기를 다른 보기와 결합합니다. 한편으로 이는 자주 사용되는 복잡한 쿼리를 저장하는 매우 편리한 방법입니다(예제에서처럼).그러나 뷰는 테이블이 아니라는 점을 기억하세요. 즉, 뷰는 데이터를 저장하지 않고 다른 테이블에서만 검색할 수 있다는 점을 기억하세요. 따라서 첫째, 테이블의 데이터가 변경되면 프레젠테이션 결과도 변경됩니다. 그리고 둘째, 뷰를 요청하면 필요한 데이터만 검색하게 되는데, 즉 DBMS의 성능이 저하된다. 그러므로 그들을 남용해서는 안됩니다.
요약하는 법을 배우자. 아니요, 이는 SQL을 연구한 결과가 아니라 데이터베이스 테이블의 열 값에 대한 결과입니다. SQL 집계 함수는 열 값에 대해 작동하여 단일 결과 값을 생성합니다. 가장 일반적으로 사용되는 SQL 집계 함수는 SUM, MIN, MAX, AVG 및 COUNT입니다. 집계 함수를 사용하는 경우를 두 가지로 구분할 필요가 있습니다. 첫째, 집계 함수는 자체적으로 사용되며 단일 결과 값을 반환합니다. 둘째, SQL GROUP BY 절과 함께 집계 함수를 사용하는데, 즉 필드(열)별로 그룹화하여 각 그룹의 결과 값을 얻는다. 먼저 그룹화하지 않고 집계 함수를 사용하는 경우를 고려해 보겠습니다.
SQL SUM 함수
SQL SUM 함수는 데이터베이스 테이블 열에 있는 값의 합계를 반환합니다. 값이 숫자인 열에만 적용할 수 있습니다. 결과 합계를 얻기 위한 SQL 쿼리는 다음과 같이 시작됩니다.
합계 선택(COLUMN_NAME)...
이 표현식 뒤에는 FROM(TABLE_NAME)이 오고 WHERE 절을 사용하여 조건을 지정할 수 있습니다. 또한, 컬럼 이름 앞에는 DISTINCT가 올 수 있는데, 이는 고유한 값만 계산된다는 의미입니다. 기본적으로 모든 값이 고려됩니다. 이를 위해 DISTINCT가 아닌 ALL을 구체적으로 지정할 수 있지만 ALL이라는 단어는 필요하지 않습니다.
MS SQL Server에서 이 단원의 데이터베이스 쿼리를 실행하고 싶지만 이 DBMS가 컴퓨터에 설치되어 있지 않은 경우 이 링크의 지침을 사용하여 설치할 수 있습니다. .
먼저 회사 데이터베이스인 Company1을 사용하여 작업하겠습니다. 이 데이터베이스와 테이블을 생성하고 테이블을 데이터로 채우는 스크립트는 이 링크의 파일에 있습니다. .
예시 1.부서와 직원에 대한 데이터가 포함된 회사 데이터베이스가 있습니다. Staff 테이블에는 직원 급여에 대한 데이터가 포함된 열도 있습니다. 표에서 선택한 내용은 다음과 같습니다(그림을 확대하려면 마우스 왼쪽 버튼으로 클릭하세요).
모든 급여의 합계를 얻으려면 다음 쿼리를 사용합니다(MS SQL Server에서 - 이전 구성 USE company1; 사용).
SELECT SUM (급여) FROM 직원
이 쿼리는 287664.63 값을 반환합니다.
그리고 지금 . 연습에서 우리는 이미 작업을 복잡하게 만들기 시작하여 실제 작업과 더 가까워졌습니다.
SQL MIN 함수
SQL MIN 함수는 값이 숫자인 열에서도 작동하며 열에 있는 모든 값의 최소값을 반환합니다. 이 함수는 SUM 함수와 유사한 구문을 갖습니다.
예시 3.데이터베이스와 테이블은 예제 1과 동일합니다.
우리는 부서 번호 42 직원의 최저 임금을 찾아야 합니다. 이를 위해 다음 쿼리를 작성합니다(MS SQL Server에서 - 접두사 USE company1; 사용).
쿼리는 10505.90 값을 반환합니다.
그리고 다시 자기 해결을 위한 연습. 이 연습과 다른 연습에서는 Staff 테이블뿐만 아니라 회사 부서에 대한 데이터가 포함된 Org 테이블도 필요합니다.

예시 4.회사 부서에 대한 데이터가 포함된 Org 테이블이 Staff 테이블에 추가됩니다. 보스턴에 위치한 부서에서 한 직원이 근무한 최소 연수를 출력하십시오.
SQL MAX 함수
SQL MAX 함수는 유사하게 작동하며 유사한 구문을 가지고 있는데, 이는 열의 모든 값 중 최대값을 결정해야 할 때 사용됩니다.
실시예 5.
부서 번호 42에 있는 직원의 최대 급여를 찾아야 합니다. 이를 수행하려면 다음 쿼리를 작성하십시오(MS SQL Server에서 - 접두사 USE company1; 사용).
쿼리는 18352.80 값을 반환합니다.
때가됐다 독립적인 해결을 위한 연습.
실시예 6.이번에도 Staff와 Org라는 두 개의 테이블을 사용하여 작업합니다. 부서명과 동부 부서 그룹(Division)에 속하는 부서의 직원 한 명이 받는 커미션의 최대 값을 표시합니다. 사용 JOIN(테이블 조인) .
SQL AVG 함수
설명된 이전 함수의 구문과 관련하여 언급된 내용은 SQL AVG 함수에도 적용됩니다. 이 함수는 열에 있는 모든 값의 평균을 반환합니다.
실시예 7.데이터베이스와 테이블은 이전 예제와 동일합니다.
부서 번호 42에 있는 직원의 평균 근속 기간을 알고 싶다고 가정해 보겠습니다. 이를 수행하려면 다음 쿼리를 작성하십시오(MS SQL Server에서 - 이전 건설 USE company1; 사용).
결과는 6.33이 됩니다.
실시예 8.우리는 하나의 테이블, 즉 직원과 함께 일합니다. 경력이 4~6년인 직원의 평균 급여를 표시합니다.
SQL COUNT 함수
SQL COUNT 함수는 데이터베이스 테이블의 레코드 수를 반환합니다. 쿼리에 SELECT COUNT(COLUMN_NAME) ...을 지정하면 결과는 열 값이 NULL(정의되지 않음)인 레코드를 고려하지 않고 레코드 개수가 됩니다. 별표를 인수로 사용하고 SELECT COUNT(*) ... 쿼리를 시작하면 결과는 테이블의 모든 레코드(행) 개수가 됩니다.
실시예 9.데이터베이스와 테이블은 이전 예제와 동일합니다.
커미션을 받는 모든 직원의 수를 알고 싶습니다. Comm 열 값이 NULL이 아닌 직원 수는 다음 쿼리에 의해 반환됩니다(MS SQL Server에서 - 접두사 USE company1; 사용).
SELECT COUNT (Comm) FROM 직원
결과는 11이 됩니다.
실시예 10.데이터베이스와 테이블은 이전 예제와 동일합니다.
테이블의 총 레코드 수를 확인하려면 별표가 있는 쿼리를 COUNT 함수에 대한 인수로 사용합니다(MS SQL Server의 경우 - 이전 구성 USE company1; 포함).
직원으로부터 개수 선택(*)
결과는 17이 됩니다.
다음에 독립적인 해결을 위한 운동하위 쿼리를 사용해야 합니다.
실시예 11.우리는 하나의 테이블, 즉 직원과 함께 일합니다. 기획부서(평원)의 직원 수를 표시합니다.
SQL GROUP BY를 사용한 집계 함수
이제 SQL GROUP BY 문과 함께 집계 함수를 사용하는 방법을 살펴보겠습니다. SQL GROUP BY 문은 데이터베이스 테이블의 열별로 결과 값을 그룹화하는 데 사용됩니다. 웹사이트에는 이 운영자에게 별도로 제공되는 레슨 .
우리는 "Ads Portal 1" 데이터베이스로 작업할 것입니다. 이 데이터베이스와 해당 테이블을 생성하고 데이터 테이블을 채우는 스크립트는 이 링크의 파일에 있습니다. .
실시예 12.그래서 광고 포털의 데이터베이스가 있습니다. 여기에는 해당 주에 제출된 광고에 대한 데이터가 포함된 광고 테이블이 있습니다. 카테고리 열에는 대규모 광고 카테고리(예: 부동산)에 대한 데이터가 포함되고, 부품 열에는 카테고리에 포함된 작은 부분에 대한 데이터가 포함됩니다(예: 아파트 및 여름 주택 부분은 부동산 카테고리의 일부임). Units 열에는 제출된 광고 수에 대한 데이터가 포함되고, Money 열에는 광고 제출로 받은 금액에 대한 데이터가 포함됩니다.
| 범주 | 부분 | 단위 | 돈 |
| 수송 | 자동차 | 110 | 17600 |
| 부동산 | 아파트 | 89 | 18690 |
| 부동산 | 다차스 | 57 | 11970 |
| 수송 | 오토바이 | 131 | 20960 |
| 건축 자재 | 무대 | 68 | 7140 |
| 전기 공학 | TV | 127 | 8255 |
| 전기 공학 | 냉장고 | 137 | 8905 |
| 건축 자재 | 레지프스 | 112 | 11760 |
| 여가 | 서적 | 96 | 6240 |
| 부동산 | 집에서 | 47 | 9870 |
| 여가 | 음악 | 117 | 7605 |
| 여가 | 계략 | 41 | 2665 |
SQL GROUP BY 문을 이용하여 각 카테고리에 광고를 게재하여 벌어들인 수익을 알아보세요. 다음 쿼리를 작성합니다(MS SQL Server에서 - 이전 구성 USE adportal1; 사용).
SELECT 카테고리, SUM(Money) AS Money FROM ADS GROUP BY 카테고리
실시예 13.데이터베이스와 테이블은 이전 예와 동일합니다.
SQL GROUP BY 문을 사용하여 각 카테고리의 어느 부분에 가장 많은 목록이 있는지 알아보세요. 다음 쿼리를 작성합니다(MS SQL Server에서 - 이전 구성 USE adportal1; 사용).
SELECT 카테고리, 부품, MAX(단위) AS 최대 FROM ADS GROUP BY 카테고리
결과는 다음 표와 같습니다.
전체값과 개별값을 하나의 테이블에서 얻을 수 있습니다. UNION 연산자를 사용하여 쿼리 결과 결합 .
관계형 데이터베이스 및 SQL 언어